
Natural language processing (NLP) is an emerging field that helps machines understand, manipulate and interpret human languages. This technology is not new, but we might not notice that it is already embedded in our everyday lives. Messaging, auto correction features, Siri, Alexa, Google Assistant and chat bots are just a few examples of applications driven by NLP combined with machine learning. NLP is a branch of Artificial Intelligence (AI) that enables the transformation of unstructured data—especially textual and speech—into valuable assets. Once processed, the data assets are analyzed to yield more meaningful patterns and insights.
The UL Standards & Engagement Data Science team is harnessing NLP to create data-driven platforms from unstructured data and the analysis of safety-related incident narratives captured by call centers or the U.S. Consumer Product Safety Commission. This technique continues to help us build algorithms that lead to the discovery of insights into incident causation and product safety. Without NLP and related techniques, these insights may remain hidden in the data.
Applying NLP to our safety data investigation and analysis has also led to significant process efficiencies and gains in productivity. In the past, our teams responsible for producing product design evaluation reports conducted product research across numerous unique safety databases. By implementing NLP and other AI related technologies, these teams can now conduct their research within a single site using this powerful search capability. As a result, the team completes its analysis faster, at a higher level of quality, and can fulfill more customer requests than ever before.
How NLP Works
In order to work with unstructured data, we need to transform it into a representable format. The transformation process is composed of multiple tasks within NLP that is simply divided into three steps: text parsing, text preprocessing and text representation.
Text parsing
Text parsing involves splitting sentences into individual words in a process called tokenization.
Text preprocessing
The resulting data from text parsing is “noisy.” This means it needs further cleansing by removing words of low relevance. We accomplish this through the following steps.
- Stop words remover: This step deletes punctuation marks, spaces, and stop words. Stop words such as “I,” “a” or “the” do not have any meaning within NLP. Their removal accelerates preprocessing and streamlines the subsequent analysis.
- Lemmatization: English words have multiple forms, such as singular and plural, which may confuse computer processes. In these cases, words are converted back to their common root form, or lemma. For example, the lemma of the words “is,” “was,” “am,” and “being” is “be.”
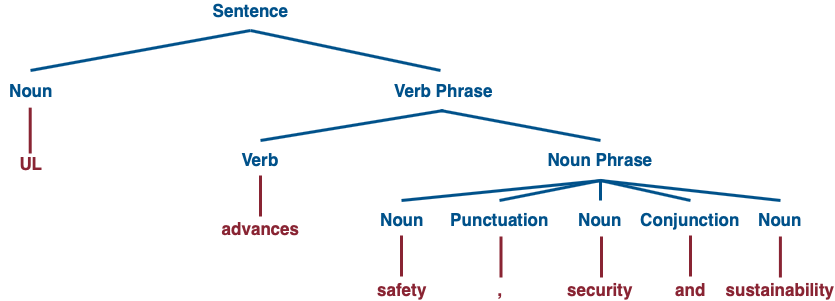
- Part-of-speech tagging: This step involves labeling the individual part-of-speech of each word. Doing so helps the algorithm recognize the structure of a sentence. For example:
Text representation
We now have clean “text,” but it needs to be transformed into a compatible format that machine learning algorithms understand before the algorithms process the data. That said, there is no specific rule about the type of text representation that works best for a specific algorithm. For example, it can depend on criteria such as the purpose of a task or compatible data.
In our recommendation engine case study below, we utilize term frequency and inverse document frequency (TF-IDF) as our text representation.
NLP in Action: A Case Study
Let’s walk through how we utilize each step of NLP in the development of a recommendation engine.
Raw text
In this example, we’ll use the following as our sample raw text/unstructured data:
UL advances safety, security and sustainability
- Step 1: Text parsing (tokenization)
- Step 2: Text preprocessing (remove stop words, punctuation and spaces)
- Step 3: Text representation
Term frequency and inverse document frequency (TF-IDF) is selected to represent our series of words to calculate similarity. TF indicates how often a term occurs in a single record, and IDF indicates how important a specific term is to a record. Once we have TF-IDF calculated, we normalize the TF-IDF value using Euclidean normalization. Doing this helps us reduce bias of length of texts and makes the text value have a similar scale across data sets.
Interested in learning more about UL Standards & Engagement Data Science? Contact us.
Fast Facts
NLP is a branch of Artificial Intelligence (AI) that enables the transformation of unstructured data—especially textual and speech—into valuable assets.
The UL Standards & Engagement Data Science team harnesses NLP to create data-driven platforms from unstructured data and the analysis of safety-related incident narratives.
Without NLP and related techniques, safety-related insights may remain hidden in the data.